instance for a decoding, i.e. [詳細]
#include <recog.h>
 RecogProcessのコラボレーション図
RecogProcessのコラボレーション図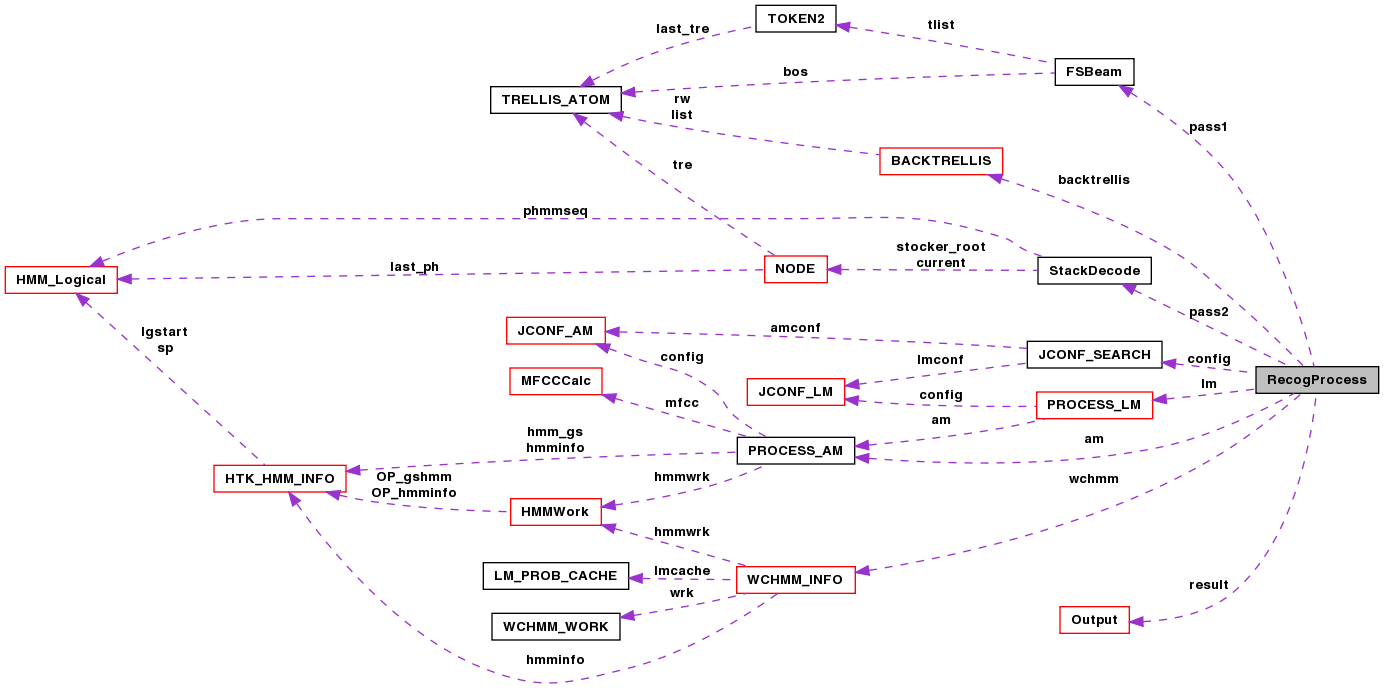
変数 | |
| boolean | live |
| TRUE is this instance is alive, or FALSE when temporary disabled. | |
| short | active |
| 1 if this instance should be made alive in the next recognition, | |
| JCONF_SEARCH * | config |
| search configuration data | |
| PROCESS_AM * | am |
| acoustic model instance to use | |
| PROCESS_LM * | lm |
| language model instance to use | |
| int | lmtype |
| Language model type: one of LM_UNDEF, LM_NGRAM, LM_DFA. | |
| int | lmvar |
| Variation type of language model: one of LM_NGRAM, LM_DFA_GRAMMAR, LM_DFA_WORD. | |
| boolean | ccd_flag |
| Whether handle phone context dependency (local copy from jconf) | |
| WCHMM_INFO * | wchmm |
| Word-conjunction HMM as tree lexicon. | |
| int | trellis_beam_width |
| Actual beam width of 1st pass (will be set on startup) | |
| BACKTRELLIS * | backtrellis |
| Word trellis index generated at the 1st pass. | |
| FSBeam | pass1 |
| Work area for the first pass. | |
| StackDecode | pass2 |
| Work area for second pass. | |
| WORD_ID | pass1_wseq [MAXSEQNUM] |
| Word sequence of best hypothesis on 1st pass. | |
| int | pass1_wnum |
| Number of words in pass1_wseq. | |
| LOGPROB | pass1_score |
| Score of pass1_wseq. | |
| WORD_ID | sp_break_last_word |
| Last maximum word hypothesis on the begin point for short-pause segmentation. | |
| WORD_ID | sp_break_last_nword |
| Last (not transparent) context word for LM for short-pause segmentation. | |
| boolean | sp_break_last_nword_allow_override |
| Allow override of last context word from result of 2nd pass for short-pause segmentation. | |
| WORD_ID | sp_break_2_begin_word |
| Search start word on 2nd pass for short-pause segmentation. | |
| WORD_ID | sp_break_2_end_word |
| Search end word on 2nd pass for short-pause segmentation. | |
| int | peseqlen |
| Input length in frames. | |
| int | graph_totalwordnum |
| GraphOut: total number of words in the generated graph. | |
| Output | result |
| Recognition results. | |
| boolean | graphout |
| graphout: will be set from value from jconf->graph.enabled | |
| char * | order_matrix |
| Temporal matrix work area to hold the order relations between words for confusion network construction. | |
| int | order_matrix_count |
| Number of words to be expressed in the order matrix for confusion network construction. | |
| boolean | have_interim |
| TRUE if has something to output at CALLBACK_RESULT_PASS1_INTERIM. | |
| void * | hook |
| User-defined data hook. | |
| struct __recogprocess__ * | next |
| Pointer to next instance. | |
説明
構造体
| short RecogProcess::active |
1 if this instance should be made alive in the next recognition,
-1 if should become dead in the next recognition, or 0 to leave unchanged.
参照元 j_launch_recognition_instance(), j_process_activate(), j_process_activate_by_id(), j_process_deactivate(), j_process_deactivate_by_id(), と j_recognize_stream_core().
search configuration data
参照元 clear_result(), decode_proceed(), detect_end_of_segment(), dfa_firstwords(), dfa_look_around(), dfa_nextwords(), do_alignment_all(), finalize_1st_pass(), find_1pass_result(), find_1pass_result_word(), get_back_trellis_init(), get_back_trellis_proceed(), get_backtrellis_words(), graph_forward_backward(), init_nodescore(), j_launch_recognition_instance(), j_process_activate(), j_process_activate_by_id(), j_process_am_remove(), j_process_deactivate(), j_process_deactivate_by_id(), j_process_lm_remove(), j_process_remove(), j_recognize_stream_core(), next_word(), ngram_acceptable(), ngram_firstwords(), pass2_finalize_on_no_result(), pick_backtrellis_words(), print_all_gram(), print_engine_info(), result_confnet(), result_graph(), result_pass1(), result_pass1_current(), result_pass1_final(), result_pass2(), result_reorder_and_output(), scan_word(), wchmm_fbs(), wordgraph_adjust_boundary(), wordgraph_compaction_exacttime(), wordgraph_compaction_neighbor(), と wordgraph_depth_cut().
acoustic model instance to use
参照元 decode_end(), decode_end_segmented(), decode_proceed(), detect_end_of_segment(), do_align(), get_back_trellis_end(), get_back_trellis_init(), hmm_check(), is_sil(), j_launch_recognition_instance(), j_recognize_stream_core(), last_next_word(), make_phseq(), malloc_wordtrellis(), next_word(), output_result(), print_engine_info(), RealTimeCMNUpdate(), result_pass2(), scan_word(), start_word(), と wordgraph_assign().
language model instance to use
参照元 bt_current_max(), bt_current_max_word(), confnet_create(), detect_end_of_segment(), dfa_acceptable(), dfa_firstwords(), dfa_nextwords(), do_align(), find_1pass_result(), find_1pass_result_word(), graph_forward_backward(), hmm_check(), init_nodescore(), is_sil(), j_launch_recognition_instance(), j_recognize_stream_core(), make_phseq(), malloc_wordtrellis(), msock_word_out1(), msock_word_out2(), multigram_build(), next_word(), ngram_acceptable(), ngram_firstwords(), ngram_nextwords(), output_result(), pick_backtrellis_words(), print_all_gram(), print_engine_info(), result_confnet(), result_graph(), result_pass1(), result_pass1_current(), result_pass2(), scan_word(), segment_set_last_nword(), send_gram_info(), set_terminal_words(), start_word(), store_result_pass2(), wchmm_fbs(), wchmm_fbs_free(), wchmm_fbs_prepare(), wordgraph_assign(), と wordgraph_check_coherence().
Language model type: one of LM_UNDEF, LM_NGRAM, LM_DFA.
参照元 detect_end_of_segment(), finalize_segment(), find_1pass_result(), get_back_trellis_init(), get_back_trellis_proceed(), init_nodescore(), is_sil(), j_launch_recognition_instance(), j_recognize_stream_core(), j_recogprocess_free(), newnode(), next_word(), output_result(), pass2_finalize_on_no_result(), print_all_gram(), print_engine_info(), result_pass1(), result_pass2(), result_reorder_and_output(), send_gram_info(), store_result_pass2(), wchmm_fbs(), wchmm_fbs_free(), wchmm_fbs_prepare(), と wordgraph_adjust_boundary().
Variation type of language model: one of LM_NGRAM, LM_DFA_GRAMMAR, LM_DFA_WORD.
参照元 bt_current_max(), clear_result(), finalize_1st_pass(), find_1pass_result_word(), get_back_trellis_init(), get_back_trellis_proceed(), init_nodescore(), j_launch_recognition_instance(), j_recognize_stream_core(), pick_backtrellis_words(), と print_engine_info().
Work area for second pass.
参照元 malloc_wordtrellis(), newnode(), pick_backtrellis_words(), result_reorder_and_output(), scan_word(), wchmm_fbs(), wchmm_fbs_free(), と wchmm_fbs_prepare().
Recognition results.
参照元 bt_current_max(), clear_result(), decode_end(), decode_end_segmented(), do_alignment_all(), finalize_1st_pass(), find_1pass_result(), find_1pass_result_word(), j_recognize_stream_core(), output_result(), pass2_finalize_on_no_result(), RealTimeCMNUpdate(), result_confnet(), result_error(), result_graph(), result_pass1(), result_pass1_current(), result_pass1_final(), result_pass2(), result_sentence_free(), result_sentence_malloc(), store_result_pass2(), と wchmm_fbs().
graphout: will be set from value from jconf->graph.enabled
参照元 clear_result(), j_launch_recognition_instance(), malloc_wordtrellis(), newnode(), scan_word(), start_word(), と wchmm_fbs().
| void* RecogProcess::hook |
| struct __recogprocess__* RecogProcess::next |
Pointer to next instance.
参照元 decode_end(), decode_end_segmented(), decode_proceed(), finalize_segment(), j_process_activate(), j_process_activate_by_id(), j_process_am_remove(), j_process_deactivate(), j_process_deactivate_by_id(), j_process_lm_remove(), j_process_remove(), j_recog_free(), j_recognize_stream_core(), j_recogprocess_new(), output_result(), print_all_gram(), print_engine_info(), RealTimeCMNUpdate(), result_confnet(), result_error(), result_graph(), result_pass1(), result_pass1_current(), result_pass1_final(), result_pass2(), と spsegment_need_restart().
この構造体の説明は次のファイルから生成されました:
- libjulius/include/julius/recog.h
