単語N-gram言語モデルの定義 [詳細]
データ構造 | |
| struct | NGRAM_TUPLE_INFO |
| N-gram entries for a m-gram (1 <= m <= N) [詳細] | |
| struct | NGRAM_INFO |
| Main N-gram structure. [詳細] | |
マクロ定義 | |
| #define | NNID_INVALID 0xffffffff |
| Value to indicate no id (full) | |
| #define | NNID_MAX 0xfffffffe |
| Value of maximum value (full) | |
| #define | NNID_INVALID_UPPER 255 |
| Value to indicate no id at NNID_UPPER (24bit) | |
| #define | NNID_MAX_24 16711679 |
| Allowed maximum number of id (255*65536-1) (24bit) | |
| #define | BEGIN_WORD_DEFAULT "<s>" |
| Default word string of beginning-of-sentence word. | |
| #define | END_WORD_DEFAULT "</s>" |
| Default word string of end-of-sentence word. | |
| #define | UNK_WORD_DEFAULT "<unk>" |
| Default word string of unknown word for open vocabulary. | |
| #define | UNK_WORD_DEFAULT2 "<UNK>" |
| #define | UNK_WORD_MAXLEN 30 |
| Maximum length of unknown word string. | |
| #define | BINGRAM_IDSTR "julius_bingram_v3" |
| Header string to identify version of bingram (v3: <= rev.3.4.2) | |
| #define | BINGRAM_IDSTR_V4 "julius_bingram_v4" |
| Header string to identify version of bingram (v4: <= rev.3.5.3) | |
| #define | BINGRAM_IDSTR_V5 "julius_bingram_v5" |
| Header string to identify version of bingram (v5: >= rev.4.0) | |
| #define | BINGRAM_HDSIZE 512 |
| Bingram header size in bytes. | |
| #define | BINGRAM_SIZESTR_HEAD "word=" |
| Bingram header info string to identify the unit byte (head) | |
| #define | BINGRAM_SIZESTR_BODY_4BYTE "4byte(int)" |
| Bingram header string that indicates 4 bytes unit. | |
| #define | BINGRAM_SIZESTR_BODY_2BYTE "2byte(unsigned short)" |
| Bingram header string that indicates 2 bytes unit. | |
| #define | BINGRAM_SIZESTR_BODY BINGRAM_SIZESTR_BODY_2BYTE |
| #define | BINGRAM_BYTEORDER_HEAD "byteorder=" |
| Bingram header info string to identify the byte order (head) (v4) | |
| #define | BINGRAM_NATURAL_BYTEORDER "LE" |
| Bingram header info string to identify the byte order (body) (v4) | |
型定義 | |
| typedef unsigned int | NNID |
| Type definition for N-gram entry ID (full) | |
| typedef unsigned char | NNID_UPPER |
| N-gram entry ID (24bit: upper bit) | |
| typedef unsigned short | NNID_LOWER |
| N-gram entry ID (24bit: lower bit) | |
関数 | |
| NNID | search_ngram (NGRAM_INFO *ndata, int n, WORD_ID *w) |
| Search for N-tuples. | |
| LOGPROB | ngram_prob (NGRAM_INFO *ndata, int n, WORD_ID *w) |
| Get N-gram probability of the last word w_n, given context w_1^n-1. | |
| LOGPROB | uni_prob (NGRAM_INFO *ndata, WORD_ID w) |
Get 1-gram probability of 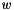 in log10. in log10. | |
| LOGPROB | bi_prob (NGRAM_INFO *ndata, WORD_ID w1, WORD_ID w2) |
| Get 2-gram probability This function is not used in Julius, since each function of bi_prob_* will be called directly from the search. | |
| void | bi_prob_func_set (NGRAM_INFO *ndata) |
| Determinte which bi-gram computation function to be used according to the N-gram type, and set pointer to the proper function into the N-gram data. | |
| boolean | ngram_read_arpa (FILE *fp, NGRAM_INFO *ndata, boolean addition) |
| Read in one ARPA N-gram file. | |
| boolean | ngram_read_bin (FILE *fp, NGRAM_INFO *ndata) |
| Read a N-gram binary file and store to data. | |
| boolean | ngram_write_bin (FILE *fp, NGRAM_INFO *ndata, char *header_str) |
| Write a whole N-gram data in binary format. | |
| boolean | ngram_compact_context (NGRAM_INFO *ndata, int n) |
| Compaction of back-off elements in N-gram data. | |
| void | ngram_make_lookup_tree (NGRAM_INFO *ndata) |
| Make index tree for searching N-gram ID from the entry name. | |
| WORD_ID | ngram_lookup_word (NGRAM_INFO *ndata, char *wordstr) |
| Look up N-gram ID by entry name. | |
| WORD_ID | make_ngram_ref (NGRAM_INFO *, char *) |
| Return N-gram ID of entry name, or unknown class ID if not found. | |
| NGRAM_INFO * | ngram_info_new () |
| Allocate a new N-gram structure. | |
| void | ngram_info_free (NGRAM_INFO *ngram) |
| Free N-gram data. | |
| boolean | init_ngram_bin (NGRAM_INFO *ndata, char *ngram_file) |
| Read and setup N-gram data from binary format file. | |
| boolean | init_ngram_arpa (NGRAM_INFO *ndata, char *ngram_file, int dir) |
| Read and setup N-gram data from ARPA format file. | |
| boolean | init_ngram_arpa_additional (NGRAM_INFO *ndata, char *bigram_file) |
| Read additional LR 2-gram for 1st pass. | |
| void | set_unknown_id (NGRAM_INFO *ndata, char *str) |
| Set unknown word ID to the N-gram data. | |
| void | print_ngram_info (FILE *fp, NGRAM_INFO *ndata) |
| Output misccelaneous information of N-gram to standard output. | |
| boolean | make_voca_ref (NGRAM_INFO *ndata, WORD_INFO *winfo) |
| Make correspondence between word dictionary and N-gram vocabulary. | |
| void | fix_uniprob_srilm (NGRAM_INFO *ndata, WORD_INFO *winfo) |
| Fix unigram probability of BOS / EOS word. | |
説明
単語N-gram言語モデルの定義
このファイルには単語N-gram言語モデルを格納するための構造体定義が 含まれています.Julius はN-gramにおいて任意の N をサポートしました.
通常の前向き (left-to-right) と後向き (right-to-left) の N-gram が サポートされています.認識の最終パス(第2パス)は後向きに行われるので, 後向き N-gram を使用することを推奨します.
第1パスの実行には前向き2-gramが必要です.前向き N-gram のみが 与えられた場合,Julius はその2-gramの部分を使います. 後向きN-gramのみが与えられた場合,Julius は 式 "P(w_2|w_1) = P(w_1|w_2) * P(w_2) / P(w_1)" にしたがって 前向き2-gramを推定します.前向きと後向きの両方指定された場合は, 前向きN-gramの2-gram部分が第1パスで用いられ,第2パスでは後向きN-gram が使われます.この両方指定したときの挙動は以前のバージョン (<=3.5.3) と同じです.
入力ファイル形式は ARPA形式とJulius独自のバイナリ形式の2つをサポートしています. 読み込みは後者のほうが高速です.前向き,後向き,両方の 全てのパターンに対応しています.
- 参照:
- mkbingram
NGRAM_INFO ではメモリ量節約のため,これらを一つの構造体で表現しています. このことから,Julius は使用するこれら2つの言語モデルが 以下を満たすことを要求します.
- 語彙が同一であること
- 各語彙の1-gram確率が同一であること
- 同じ 2-gram tuple 集合が定義されていること
- 3-gram のコンテキストである単語組の2-gramが定義されていること
上記の前提のほとんどは,これらの2つのN-gramを同一のコーパスから 学習することで満たされます.最後の条件については,3-gram のカットオフ 値に 2-gram のカットオフ値と同値かそれ以上の値を指定すればOKです. 与えられたN-gramが上記を満たさない場合,Julius はエラーを出します.
- 日付:
- Fri Feb 11 15:04:02 2005
- Revision:
- 1.10
ngram2.h で定義されています。
関数
| NNID search_ngram | ( | NGRAM_INFO * | ndata, |
| int | n, | ||
| WORD_ID * | w | ||
| ) |
Search for N-tuples.
- 引数:
-
ndata [in] word/class N-gram n [in] N of N-gram (= number of words in w) w [in] word sequence
- 戻り値:
ngram_access.c の 103 行で定義されています。
参照元 add_bigram(), と set_ngram().
| LOGPROB ngram_prob | ( | NGRAM_INFO * | ndata, |
| int | n, | ||
| WORD_ID * | w | ||
| ) |
Get N-gram probability of the last word w_n, given context w_1^n-1.
- 引数:
-
ndata [in] word/class N-gram n [in] N of N-gram (= number of words in w) w [in] word sequence
- 戻り値:
ngram_access.c の 135 行で定義されています。
参照元 ngram_forw2back(), ngram_prob(), と pick_backtrellis_words().
| LOGPROB uni_prob | ( | NGRAM_INFO * | ndata, |
| WORD_ID | w | ||
| ) |
Get 1-gram probability of in log10.
- 引数:
-
ndata [in] word/class N-gram w [in] word/class ID in N-gram
- 戻り値:
- log10 probability
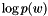 .
.
ngram_access.c の 229 行で定義されています。
参照元 build_wchmm(), build_wchmm2(), max_successor_prob(), と ngram_firstwords().
| LOGPROB bi_prob | ( | NGRAM_INFO * | ndata, |
| WORD_ID | w1, | ||
| WORD_ID | w2 | ||
| ) |
Get 2-gram probability This function is not used in Julius, since each function of bi_prob_* will be called directly from the search.
- 引数:
-
ndata [in] N-gram data that holds the 2-gram w1 [in] left context word w2 [in] right target word
- 戻り値:
- the log N-gram probability P(w2|w1)
ngram_access.c の 419 行で定義されています。
| void bi_prob_func_set | ( | NGRAM_INFO * | ndata | ) |
Determinte which bi-gram computation function to be used according to the N-gram type, and set pointer to the proper function into the N-gram data.
- 引数:
-
ndata [i/o] N-gram information to use
ngram_access.c の 449 行で定義されています。
参照元 ngram_read_arpa(), と ngram_read_bin().
| boolean ngram_read_arpa | ( | FILE * | fp, |
| NGRAM_INFO * | ndata, | ||
| boolean | addition | ||
| ) |
Read in one ARPA N-gram file.
Supported combinations are LR 2-gram, RL 3-gram and LR 3-gram.
- 引数:
-
fp [in] file pointer ndata [out] N-gram data to store the read data addition [in] TRUE if going to read additional 2-gram
- 戻り値:
- TRUE on success, FALSE on failure.
ngram_read_arpa.c の 538 行で定義されています。
| boolean ngram_read_bin | ( | FILE * | fp, |
| NGRAM_INFO * | ndata | ||
| ) |
Read a N-gram binary file and store to data.
- 引数:
-
fp [in] file pointer ndata [out] N-gram data to store the read data
- 戻り値:
- TRUE on success, FALSE on failure.
ngram_read_bin.c の 594 行で定義されています。
参照元 init_ngram_bin().
| boolean ngram_write_bin | ( | FILE * | fp, |
| NGRAM_INFO * | ndata, | ||
| char * | headerstr | ||
| ) |
Write a whole N-gram data in binary format.
- 引数:
-
fp [in] file pointer ndata [in] N-gram data to write headerstr [in] user header string
- 戻り値:
- TRUE on success, FALSE on failure
ngram_write_bin.c の 135 行で定義されています。
| boolean ngram_compact_context | ( | NGRAM_INFO * | ndata, |
| int | n | ||
| ) |
Compaction of back-off elements in N-gram data.
- 引数:
-
ndata [i/o] N-gram information n [i] N of N-gram
- 戻り値:
- TRUE on success, or FALSE on failure.
ngram_compact_context.c の 39 行で定義されています。
参照元 ngram_read_arpa().
| void ngram_make_lookup_tree | ( | NGRAM_INFO * | ndata | ) |
Make index tree for searching N-gram ID from the entry name.
- 引数:
-
ndata [in] N-gram data
ngram_lookup.c の 35 行で定義されています。
参照元 ngram_read_bin().
| WORD_ID ngram_lookup_word | ( | NGRAM_INFO * | ndata, |
| char * | wordstr | ||
| ) |
Look up N-gram ID by entry name.
- 引数:
-
ndata [in] N-gram data wordstr [in] entry name to search
- 戻り値:
- the found class/word ID, or WORD_INVALID if not found.
ngram_lookup.c の 65 行で定義されています。
参照元 add_bigram(), add_unigram(), make_ngram_ref(), ngram_read_arpa(), set_ngram(), と set_unknown_id().
| WORD_ID make_ngram_ref | ( | NGRAM_INFO * | ndata, |
| char * | wstr | ||
| ) |
Return N-gram ID of entry name, or unknown class ID if not found.
- 引数:
-
ndata [in] N-gram data wstr [in] entry name to search
- 戻り値:
- the found class/word ID, or unknown ID if not found.
ngram_lookup.c の 85 行で定義されています。
参照元 make_voca_ref().
| NGRAM_INFO* ngram_info_new | ( | ) |
Allocate a new N-gram structure.
- 戻り値:
- pointer to the newly allocated structure.
ngram_malloc.c の 34 行で定義されています。
参照元 initialize_ngram().
| void ngram_info_free | ( | NGRAM_INFO * | ndata | ) |
| boolean init_ngram_bin | ( | NGRAM_INFO * | ndata, |
| char * | bin_ngram_file | ||
| ) |
Read and setup N-gram data from binary format file.
- 引数:
-
ndata [out] pointer to N-gram data structure to store the data bin_ngram_file [in] file name of the binary N-gram
init_ngram.c の 36 行で定義されています。
参照元 initialize_ngram().
| boolean init_ngram_arpa | ( | NGRAM_INFO * | ndata, |
| char * | ngram_file, | ||
| int | dir | ||
| ) |
Read and setup N-gram data from ARPA format file.
- 引数:
-
ndata [out] pointer to N-gram data structure to store the data ngram_file [in] file name of ARPA (reverse) 3-gram file dir [in] direction (DIR_LR | DIR_RL)
init_ngram.c の 65 行で定義されています。
参照元 initialize_ngram().
| boolean init_ngram_arpa_additional | ( | NGRAM_INFO * | ndata, |
| char * | bigram_file | ||
| ) |
Read additional LR 2-gram for 1st pass.
- 引数:
-
ndata [out] pointer to N-gram data structure to store the data bigram_file [in] file name of ARPA 2-gram file
init_ngram.c の 98 行で定義されています。
参照元 initialize_ngram().
| void set_unknown_id | ( | NGRAM_INFO * | ndata, |
| char * | str | ||
| ) |
Set unknown word ID to the N-gram data.
- 引数:
-
ndata [out] N-gram data to set unknown word ID. str [in] word name string of unknown word
init_ngram.c の 169 行で定義されています。
参照元 initialize_ngram().
| void print_ngram_info | ( | FILE * | fp, |
| NGRAM_INFO * | ndata | ||
| ) |
Output misccelaneous information of N-gram to standard output.
- 引数:
-
fp [in] file pointer ndata [in] N-gram data
ngram_util.c の 79 行で定義されています。
参照元 print_engine_info().
| boolean make_voca_ref | ( | NGRAM_INFO * | ndata, |
| WORD_INFO * | winfo | ||
| ) |
Make correspondence between word dictionary and N-gram vocabulary.
- 引数:
-
ndata [i/o] word/class N-gram, the unknown word information will be set. winfo [i/o] word dictionary, the word-to-ngram-entry mapping will be done here.
init_ngram.c の 127 行で定義されています。
参照元 initialize_ngram().
| void fix_uniprob_srilm | ( | NGRAM_INFO * | ndata, |
| WORD_INFO * | winfo | ||
| ) |
Fix unigram probability of BOS / EOS word.
This function checks the probabilities of BOS / EOS word, and if it is set to "-99", give the same as another one. This is the case when the LM is trained by SRILM, which assigns unigram probability of "-99" to the beginning-of-sentence word, and causes search on reverse direction to fail.
- 引数:
-
ndata [i/o] N-gram data winfo [i/o] Vocabulary information
init_ngram.c の 206 行で定義されています。
参照元 initialize_ngram().
